")
")
Open Access
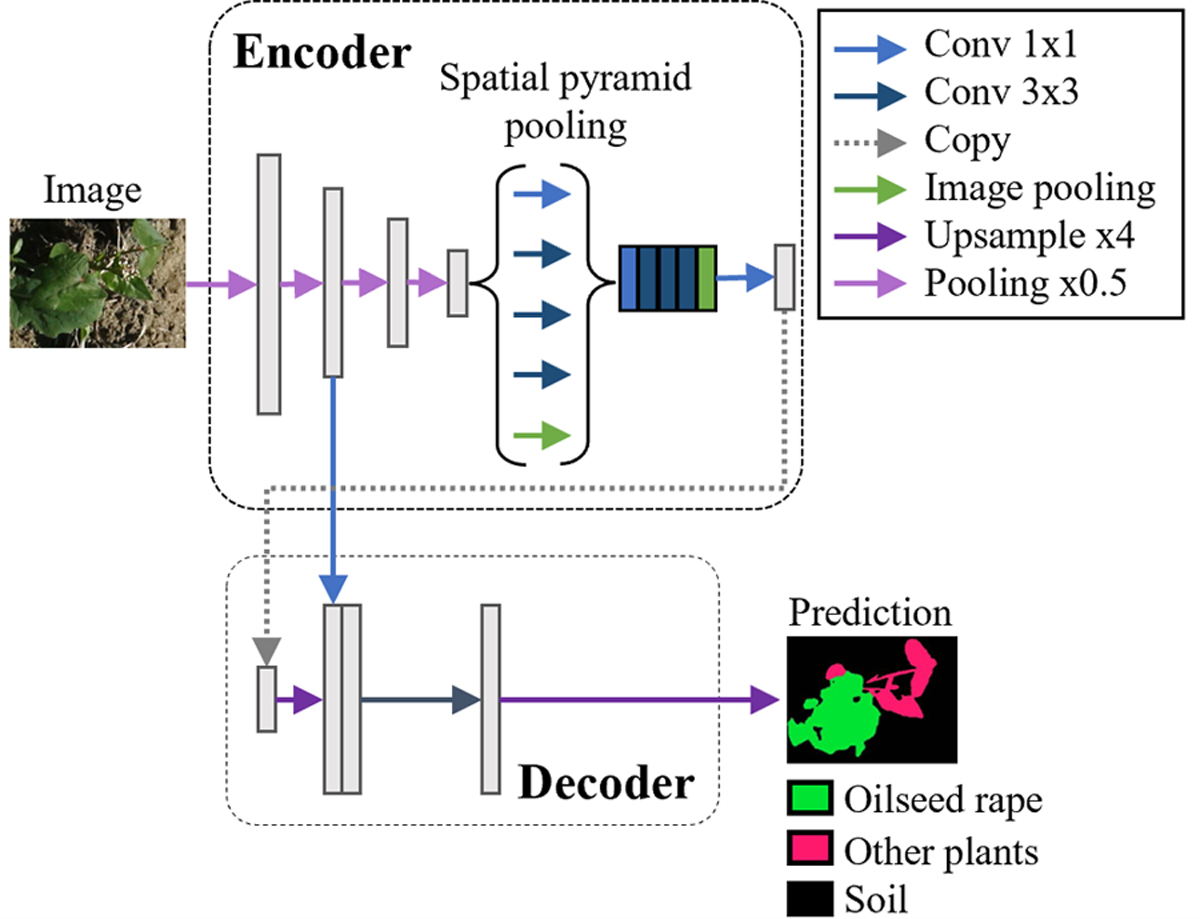
Fig. 2
Download original image
DeepLabv3+ proposed by Chen et al. (2018a) extends DeepLabv3 by employing a encoder-decoder structure. The encoder module encodes multi-scale contextual information by applying dilated convolution at multiple scales, while the simple yet effective decoder module refines the segmentation results along object boundaries.
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.